
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- AWS실습
- 리눅스기초명령어
- 리눅스명령어
- 최소권한
- Linux
- aws
- 쉘스크립트
- terraform with aws
- linux명령어
- AWS CI/CD
- cissp
- 리눅스
- terraform기본
- terraform따라하기
- 주피터노트북 설치
- AWS배포자동화
- aws terraform
- aws기본
- aws기초
- aws따라하기
- 리눅스기초
- AWS CodeDeploy
- GDPR
- AWS 공격테스트
- Cissp sdlc
- blue/green배포
- terraform기초
- 직무분리
- opt/anaconda3/bin/jupyter_mac.command
- AWS구축
ysuekkom의 IT study note
Splunk Architecture 이해하기 본문
인프라를 운용에 있어 분석 및 모니터링은 필수적이다. 이를 위해 여러가지 프로그램과 툴이 존재한다.
AWS 내에서도 여러 서비스를 통해 트래픽과 데이터를 분석하고, 위험 및 위협 방지를 수행한다. 트래픽에 대한 인사이트를 알람으로 제시하고, 미리 설정한 셋팅으로 가용성과 복원력을 보장하고 있다.
Splunk에 대해 기본적인 것부터 알아보자.
Splunk?
빅데이터 분석에 관련된 SW 플랫폼으로 데이터의 수집, 가공, 정제 및 시각화, 모니터링을 구현할 수 있다.
왜 Splunk를 사용해야 할까.
-다운타임 감소: 모든 시스템에 대한 가시성을 제고앟여, 비즈니스에 영향을 미치기 전 사고 대응을 가능하게 한다. 시간과 리소스를 절약하기 위한 알림처리 및 작업 자동화를 수행할 수 있다.
-빠른 복원력: 빠른 탐지 및 응답 시간으로 WorkFlow의 간소화 및 표준화를 가능하게 한다.
-신규 앱 출시 시간 단축: 새로운 구성 및 환경 설정 변화가 미치는 영향에 대한 분석 수행 및 가시성을 제공한다.
서비스 모델에 따라서 위험에 대한 단계별 임계치를 설정하고, 이슈 발생 시 빠르게 인지해야 한다.
이후, 이슈에 대한 원인과 추후 분석을 통해 근본 원인과 해소를 위한 작업이 필요하다. 이를 위해서 분석을 위한 로그데이터와 이를 효과적으로 가공하여 필요한 정보를 빠른 시간 내 분석해야한다.
즉 시스템에 대한 설계, 망 설계 그리고 운용 엔지니어, 관제 인력 등의 협력이 필수적이다. 이슈 발생 전 예방제어, 발생 시 빠른 선조치, 발생 이후 원인 분석과 추후 조치를 수행하게 되기 때문에 유기적으로 움직인다. 미션 크리티컬한 시스템의 안정적인 설계와 운용이 서비스 연속성을 보장하는 핵심이 되는 것이다.
효과적으로 분석 및 예방할 수 있도록 도와주는 Splunk의 아키텍처에 대해 알아보자.
Splunk 아키텍처

- Universal Forwarder
-Client에서 데이터 (보통 웹 서버와 함께 구성되어있음), 실시간 수집 가능하며, 로컬(Application, End-Device 등) 모니터링 가능
-특정 경로의 파일(access.log, error.log 등)을 지속 모니터링 한다는 정보를 inputs.conf에 설정
-IDX의 특정 포트로 데이터를 보내는 정보를 outputs.conf에 설정(outputs.con를 통해 지정된 IDX로 전송하게 되면 IDX에 데이터가 쌓이게 됨)
-AutoLB=t, LoadBalancingForwarder를 통해 특정 주기로 IDX에 분배하는 설정 등을 추가할 수 있음
>>Heavy Forwarder
-로그의 민감 정보를 마스킹하여 IDX로 전송
-DB 연동 시, DB Connector App(DBX)를 통해 job 관리 및 IDX LB 수행
-UF 바이너리를 사용할 수도, Splunk Enterprise 바이너리를 사용할 수도 있음
- Indexer
-$splunkDB, file형태로 쌓이게 됨
-쌓은 로그들을 문자열 기준, Reverse Indexing 수행(log data를 압축(journal.gz), tsidx로 정보를 저장(빠르게 필요한 정보를 검색할 수 있음)
-데이터 보관 주기 Hot/Warm/Cold 등 retention 주기 관리
-Index Cluster로 가용성 확보: UF로부터 데이터 받을 때, 미리 설정된 Search Peer IDX에게 데이터 복제본(journal.gz, tsidx 전송/ RF&SF)
>>Index Cluster
-최소 3개 이상의 IDX로 구성됨
-특정 IDX 장애 발생 시, Index Cluster가 Serach Peer로 전송한 복제본으로 가용성 확보
-모든 IC는 LM과 연동되어 있음
- Search Header
-사용자는 Search Head를 통해 검색, S.H는 해당 데이터셋을 가진 IDX에서 필요한 정보만 가져옴
-SH는 CM(Cluster Master)와 Topology 정보를 공유하며, CM은 Topology 정보와 복제본에 대한 관리를 수행함
-SHCluster는 Search Artifacts 결과값과 설정 정보 등을 공유함
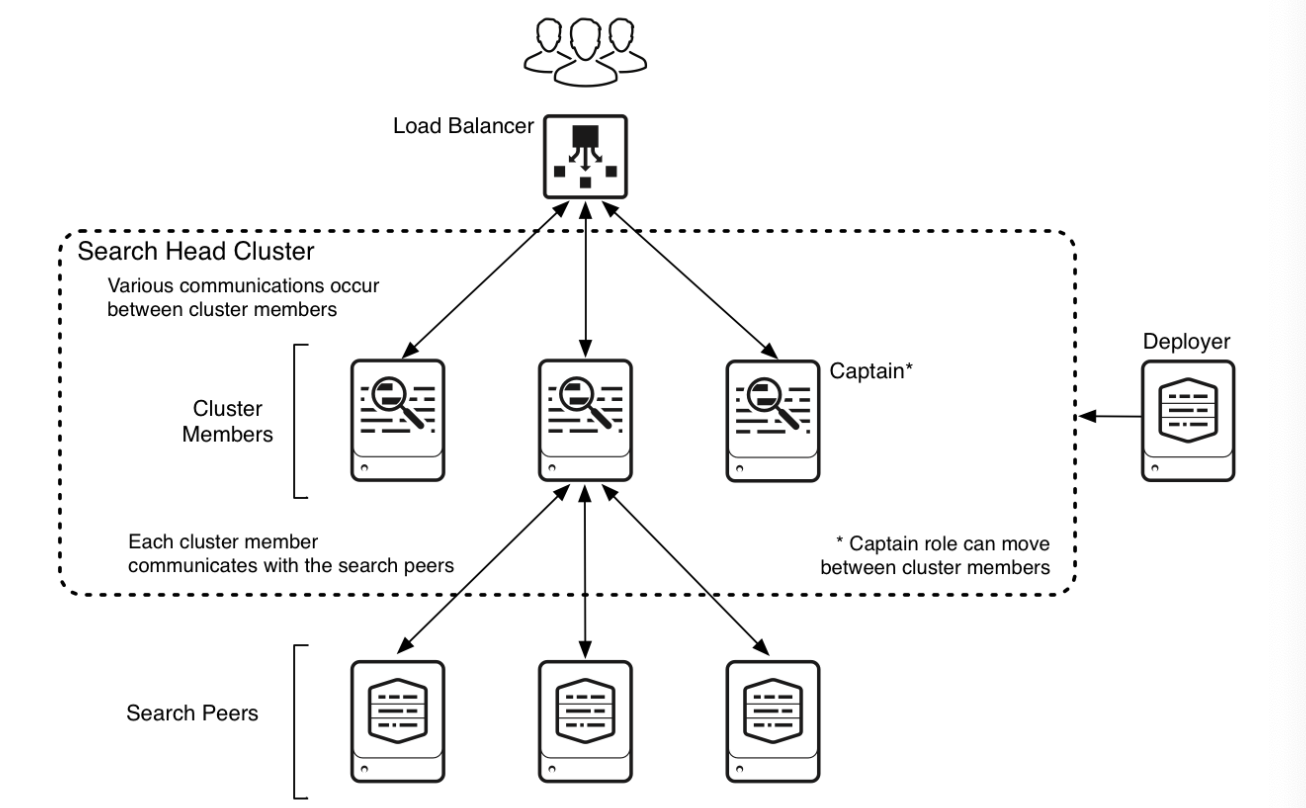
>>Search Head Cluster
검색을 위한 중앙 리소스 역할을 하는 Splunk Enterprise Search Head Group로, configurations, job scheduling, search artifacts값을 공유한다.
-하나의 SH가 클러스터 내 Captain 역할을 수행: 모든 구성원 간 job, 노드 별 분산 관리 복제 활동 등을 조정하면서 SH 기본기능도 수행
-검색 요청을 위해 Search Peer와 통신함
- Management
>>Deployment Server
-UFs 관리(App 배포 등)
-Search head Cluster 관리
>>Cluster Master
-IDX App 배포 및 관리
-Search Head와 토폴로지 정보 공유
>>Deployer
Search Head들의 App을 동시에 배포하는 역할 수행, 별도의 인스턴스로 구성됨
- Monitoring Console
-모든 SH, IDX, UFs 등 관리 및 모니터링
-Splunk Health Check 등
-mgnt와는 별도로 구성됨
다중 클러스터링 구축 예시1,2 비교
데이터를 둘 이상의 그룹에 복제 사이트(DR)을 구성하여, 데이터가 복제되는지 확인한다. 다중 클러스터링을 구축할 시, IDX 용량, 단일 사이트 관리 여부, 데이터 중복성 제공 여부 등에 대한 설정을 할 수 있다.

-수평 확장성 및 단일지점 제거
-Search Head Cluster의 HA 보장 의무 없음
-최적의 FailOver 보장하지 않음
-사이트간 Artifacts 복제 없으며, SHC는 독립 실행 수행

-고가용성(HA) 및 재해 복구, 서비스 연속성 보장
-인프라 운영, 수집, 인덱싱 및 검색 기능 보장
-두 개 이상의 Search Head Cluster로 스캐너 검색, 사용자에게 최적의 FailOver를 제공함
-클러스터 전체에서 사용자 LB 가능
참고
https://www.splunk.com/en_us/pdfs/tech-brief/splunk-validated-architectures.pdf